21 Apr Character encoding - the bane of my existence
During the soft launch of Free Pee 2, I ran into a weird problem. Bathrooms that had Chinese descriptions wouldn't show up. Immediately, I thought of character encodings and database collation - but it didn't feel right because everything worked correctly in the original Free Pee app. Why did it suddenly stop working?
After lots of Google searches and Stack Overflow answers, I added $db->set_charset("utf8") to my mysqli object. It turned out that didn't solve the problem either. Finally, after almost giving up hope, I decided to re-save all my app files as UTF-8 (even though they've never been anything but UTF-8). To my surprise, that worked. I shrugged and moved on.
Today, I decided to write a blog post since I didn't write anything this year yet (!). I noticed some garbled text in posts and comments.

I exported the database and looked at the SQL it generated.

Things were not looking so great. Remembering my last experience with character encoding, I immediately saved all my files as UTF-8 again and redeployed. It didn't work. I added set_charset to my main database object. That didn't work either.
I ended up finding a post on Stack Overflow that mentioned we should be using utf8mb4_unicode_520_ci instead of any form of utf8 in MySQL since utf8 as defined by MySQL is limited and leaves out some emojis and Chinese. Turns out that didn't work either. Note that I'm not sure how safe it is to change the collation of a database in production, but I was desperate: all my non-English characters were gone anyway, though I did export a copy of my database just in case.
In my desperation, I copied a small piece of garbled text out of the database and fed it into this awesome decoder. I then went through all the possible encode-decode pairs.
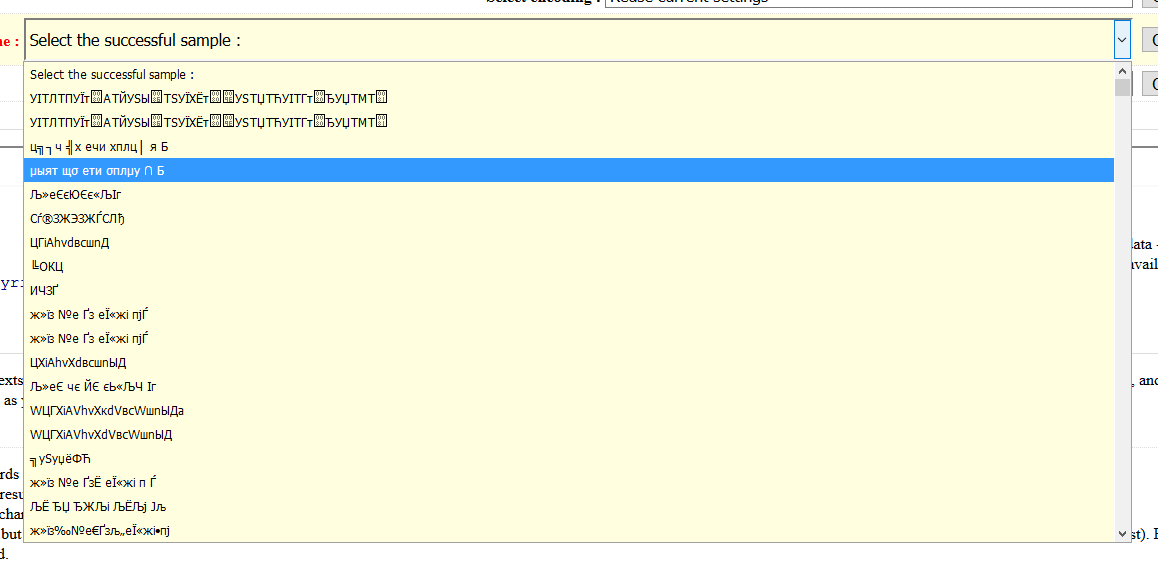
Finally, I found the one that showed the right text. It was encoded as UTF-8 in the source (as it should be), and output as WINDOWS-1252. What?! How does that just "suddenly" happen by itself?

I then wrote this piece of code to convert a whole bunch of other things that weren't WINDOWS-1252 from Unicode strings to actual Chinese symbols.
const fs = require('fs');
const text = fs.readFileSync('db.sql', 'utf8');
function unicodeToSymbol(text) {
return text.replace(/\\u[\dA-F]{4}/gi, match =>
String.fromCharCode(parseInt(match.replace(/\\u/g, ''), 16)));
}
console.log(unicodeToSymbol(text));
I hope you all learned something from my experiences here!
Comments
This is so interesting! Thanks for sharing Michael :)